今天【数字媒体技术】课程说到图像文件结构
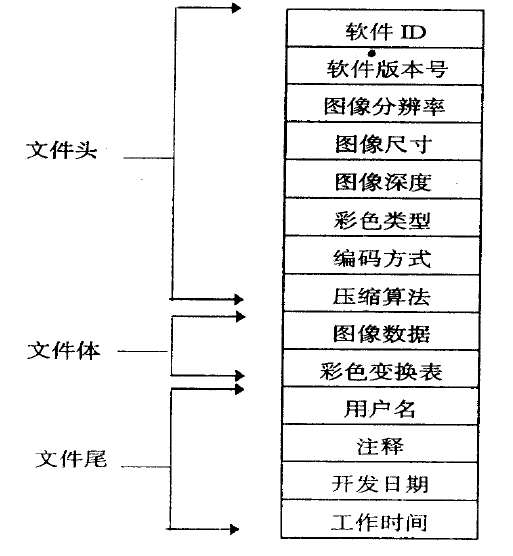
还展示了如何查看图片信息,提醒我们可以通过照片获取很多信息,需谨慎保存照片…以及拍照时要关闭GPS,否则会在照片上留下位置信息。
回来试了一下,用三种方式查看图片信息
今天【数字媒体技术】课程说到图像文件结构
还展示了如何查看图片信息,提醒我们可以通过照片获取很多信息,需谨慎保存照片…以及拍照时要关闭GPS,否则会在照片上留下位置信息。
回来试了一下,用三种方式查看图片信息
这周开始做C语言笔试卷,什么嘛!考的都是概念,各种细节,虽然貌似书上都能找到,但我还真不清楚…顿时又有一种我C语言学的好渣的感觉 T_T
好了,说下在【上机实验蓝皮书背后,综合测试题二】中难到的2道题,这两道题使得你对【指针数组】和【数组指针】的区别更加清晰。
【例题1】
有以下程序:
#include
int main()
{
char *s[] = {"one", "two", "three"}, *p;
p = s[1];
printf("%c, %s\n",*(p+1), s[0]);
return 0;
}
执行后的结果是_______。
A. n, two B. w, one C. t, one D. o, two
第一次我选了 C,因为我以为 (p+1) 是指向 “three“ 的。这是对指针 p 类型的理解错误。
正确答案是 B,因为:
#include
int main()
{
char *s[] = {"one", "two", "three"}; // s是一个指针数组,元素是3
// 个指向字符串常量的指针
char *p = s[1]; // p是一个指向字符串的指针变量
printf("%c, %s\n",*(p+1), s[0]);
// (p+1)是p的地址加一个字符内存的大小,从指向t变成指向w
return 0;
}
所以,平时我们说的指向字符串的指针,其实都是指向一个字符,所以对它进行位移运算时,加减都是1。
另外,如果你把第8行
printf("%c, %s\n",*(p+1), s[0]);
改成
printf("%c, %s\n",*p, s[0]);
输出就会是:wo,one
因为平时我们输出字符串的时候,实际上都是把字符串的首地址传给 printf( ) 函数,它通过末尾的 ‘\n’,来判断是否结束。
【例题2】
#include
int main()
{
int a[3][4] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
int (*p)[4] = a;
printf("%d\n", *(*(p+1)+3));
return 0;
}
以上代码执行的结果是_______。
答案是 8
这道题初看我完全不理解…怎么*了还能*,(*p)[4]又是什么鬼…我做这份卷子前把【指针数组】和【数组指针】搞乱了=
是这样的:
1.(*p)[4]:声明p是一个指向(4个int元素的数组)的指针,因此 p+1 从指向 a[0],变成指向 a[1]
2.*(*(p+1)+3):为什么会有两个星?
*(p+1) => a[1][0](也就是5),第一星从a[1]变成a[1][0],这个过程虽然地址没有变,但指针的类型变了!原来指针+1是加4个 int,现在指针+1只加一个 int 了!!
*(p+1)+3 => a[1][3](也就是8),再取一个*就是从地址里读出8
还可以修改一下原来的代码弄清楚:
#include
int main()
{
int a[3][4] = {{1,2,3,4}, {5,6,7,8}, {9,10,11,12}};
int (*p)[4] = a;
printf("p: %p\n",p);
printf("p+1: %p\n",p+1);
printf("*(p+1): %p\n",*(p+1));
printf("*(p+1)+3: %p\n",*(p+1)+3);
printf("%d\n",*(*(p+1)+3));
return 0;
}
输出的结果是:
p: 0x7fff9f4ba180
p+1: 0x7fff9f4ba190
*(p+1): 0x7fff9f4ba190
*(p+1)+3: 0x7fff9f4ba19c
8
好啦~
这篇笔记最早发在博客园里,直接粘贴过来再排版的,所以格式不太美观,可以看→原文
上周我一直在通过看书、实践来试图弄懂指针。
一直到学习指针之前,我几乎都是不看书的。也没有看老师上课的PPT,因为感觉老师的PPT经常有错误,上课用还凑合,但自己课下看实在是很不舒服。我手头上有两本教材,一本是科大自己的《计算机程序设计(C语言版)》(机械工业出版社的),另一本是C语言经典教材《C程序设计语言(第二版)》是 The C Programming Language 翻译过来的。
按说第二本显然更好。因为LUG里面众人的吐槽和推荐,我不是很相信学校的教材,你看全书代码风格都不统一。而第二本虽说好,之前在阮一峰的博文 C语言学习教材 上面看到,并不适合新手。= =
上周C指针的学习,一开始是看经典教材的,结果看到字符指针就看不懂了,主要是作者为了引入字符指针举了个非常麻烦的例子。几乎看不懂!!
我发现C语言教材有这样的问题,它假设你之前的部分都看过了,所以不时的引入之前的内容而且不附加说明。造成的结果,你即使按照教材上面的代码输了一遍也往往跑不起来。
反正,最后放弃 The C Programming Language 我也认为它太难,太生涩,对新手不友好!相反,上周最后发现,学校的这本教材对指针的解释还可以接受=。就决定看这个了,感觉C指针还是需要资料的指导的。
所以,不仅人和人之间的信任是很重要的,对书本的信任也是很重要的…
字符指针,也就是指向字符数组(字符串常量)的指针,比起指向数组的指针有略微不同。似乎是因为字符串常量特有的性质。还是通过代码来说明好了。
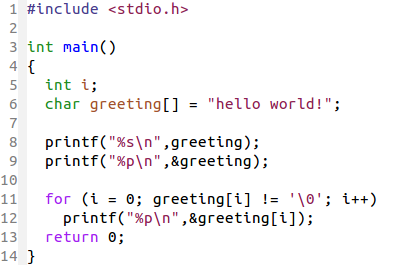
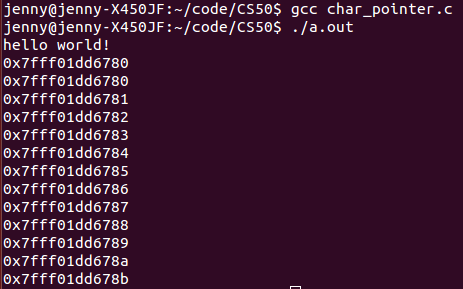
以上操作,并没有体现出字符数组和之前我们学过的数组有什么不同。我只是想看看字符数组的地址啦~(看地址强迫症)
先回顾一下指向数组的指针
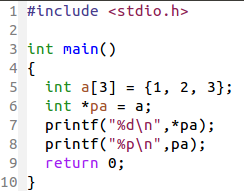
pa 是指向数组 a 的指针变量
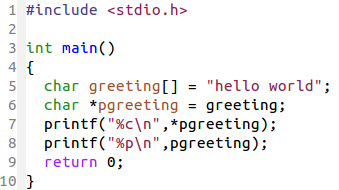
pgreeting 是指向字符数组 greeting 的指针变量
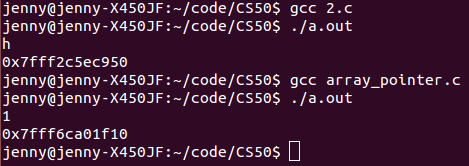
所以,从输出来看,指向数组的指针变量和指向字符数组的指针变量没什么区别嘛!输出的地址都差不多长= = 其他的一些操作也应该一样。
以上操作实在没搞懂字符指针和普通的指向数组的指针有什么区别…
但字符指针可以这么操作:
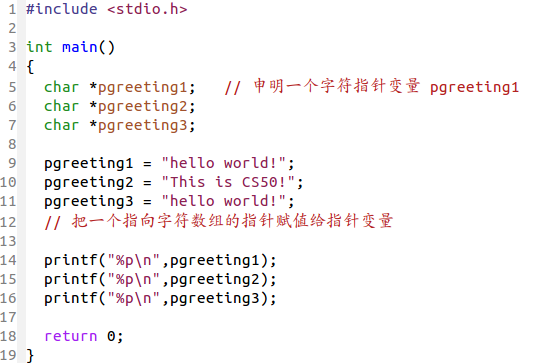

如果字符指针有特殊之处,就在于它特殊的赋值方式…… 也就是第9-11行,右边写的是字符串常量却代表的是字符数组的指针。
另外还有的就是,由于这样:这些字符指针变量是指向字符串常量的指针,由于常量和变量的储存位置不同,地址要短很多。而还有的就是,两个指向”hello world!”的地址是一样的。
这些应该都是C语言实现的问题。
课本上说,下图第5行的语句中,printf 接受的是一个指向字符数组第一个字符的指针。也就是字符串常量可通过一个指向其第一个元素的指针访问。
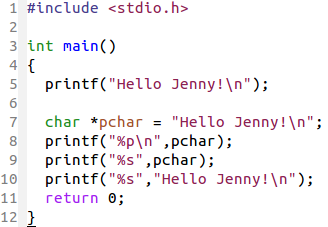
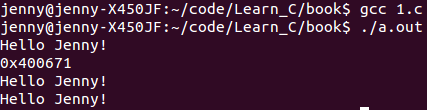
好,我们看下以上的代码,pchar 是指向字符串常量第一个元素的指针,它的地址是 0x400671,然后我们可以通过 %s,pchar 来输出这之后的字符,直到遇到 ‘\0’。
所以,以上第9行和第10行应该是等价的,而第5行应该是它们的缩写。感觉上9、10行的写法更规范一些。
学习数组的时候老师强调,数组是在内存空间上连续分布的一群相同数据类型的元素的集合。图中,数组并没有初始化,但运行时仍然分配了内存
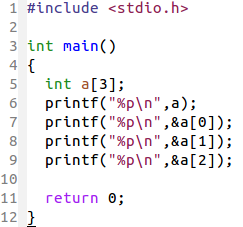
的确是这样,并且数组名 a (它的值是地址)和数组第0个元素 a[0] 地址是一样的。

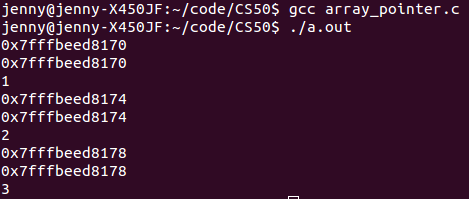
以上代码和运行结果就说明了,申明一个指针 pa 指向数组 a 后:
事实上,即使你让数组越界也不会有什么事情发现,地址输出仍然是正确的,只是值是不可预知的。如下代码所示:
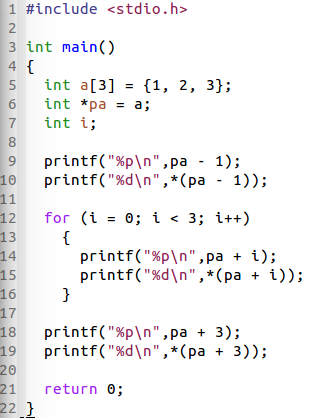
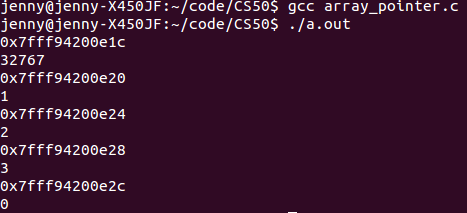
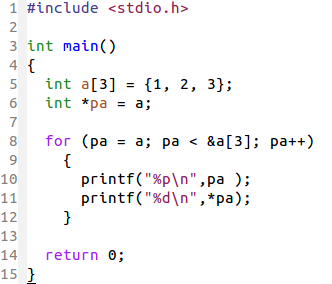
指向数组的指针没什么特别的。如下,我们可以用指针变量 pa 作为条件判断依据:
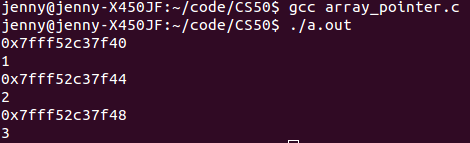
数组名是数组首个元素的地址,但不是指针变量。它和指针变量是有区别的!如下:
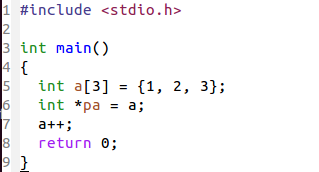

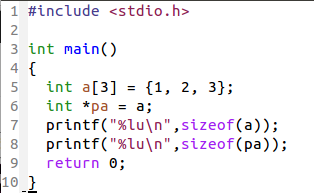

1.pa 是个变量,可以 pa++ 而 a++ 是非法的。
2.sizeof(数组名)得到的是数组的大小,而sizeof(指针)得到的就是指针的大小啦!
总的来说,数组名更像是指针,而不是指针变量
老师说过,指针是指针变量的值。似乎还说过指针和地址是等价的。我们说指针变量是有类型的(那么指针也有类型?),虽然我不是很清楚指针和地址的更多区别,但为了避免混淆,我们还是尽量明确“指针变量”,感觉平时说的“指针”,很多时候是指“指针变量”…这里只是提一下。
PS:接下来这部分内容主要参考<The C Programming Language>(C程序设计语言-第2版)来写
这篇文章对应于 第83页 5.3 指针与数组
第5.4 地址算术运算,这部分我没看懂….先跳过了
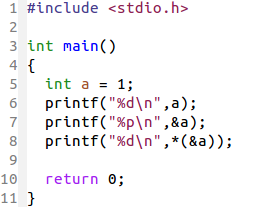
指针的定义


如何printf一个指针呢?指针的格式控制字符是 %p

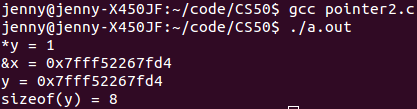
嗯,从输出结果知道:我的64位(bit)机器上地址大小是8字节(byte)(8 byte = 64 bit)
O(∩_∩)O哈!新技能get√!!以后一定要多多输出指针,当搞不清楚指针到底指向哪里的时候,不妨输出地址看看嘛!

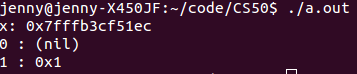
我们看上图中 x 的地址是 0x 开头的一串字符,也就是十六进制数。地址在计算机中是独一无二的,没有重复的地址,地址的大小在 [0, 2^64 – 1]范围内
2进制64位数字用16进制表示应该有16位,因为每相邻4位数可以等价于1位16进制位。而x的地址之所以不足16位是因为:它把前面的0省略了。我们还可以看到,地址0是(nil),地址1是0x1。
首先,常用运算符的优先级是这样的:
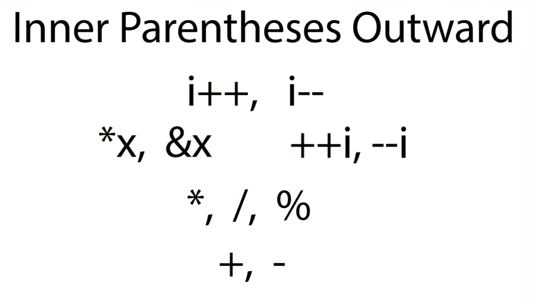
我们知道 i++ 和 ++i 是不一样的:
i++
which means that the current value is used in the expression, and then it is incremented
++i
the current value is incremented first, and then it is used in the expression.
举例:


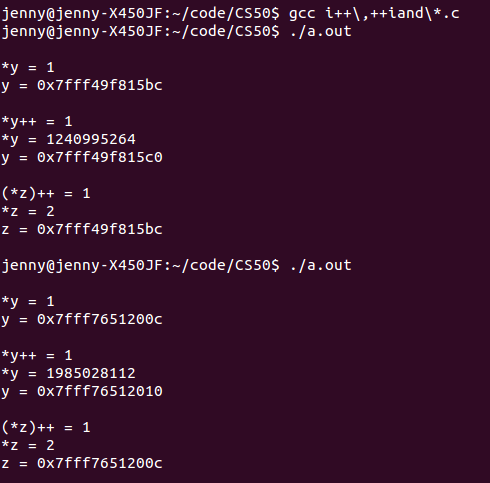
现在我们看下 * 的优先级:


以上的代码就能说明 *y++ 的执行顺序是从右到左的
这部分代码说明的问题还是很好玩的,我们来解读一下:
好啦,最后还有一个新的发现:可执行文件每执行一次,内存地址就重新分配一次!
另外刚刚尝试了这个
* 和 & 互为逆运算
一、你知道编译的时候发生了什么吗?
你知道C语言编译时发生了什么吗?
是不是像我一样嫌弃老师上课讲的冗长又抽象,搞什么嘛!
说那么多还不如把细节展示给我看!
这周的Shorts视频中有一集叫做Compilers,7分钟不仅详细讲了编译时的四个步骤,还打开查看了 -E -S -c之后的文件。看完感到极大的满足,于是动手试了一遍,下面把视频转换成图文,跟我一起学C语言啦!

首先,写一个大家非常熟悉的”hello world!”代码

哦,我用的编辑器是emacs,操作系统是ubuntu(linux),然后直接在终端(Terminal)下用gcc编译,然后 ./a.out 执行。运行正常
这就完成了一次编译到运行的操作。平时我做作业也都是这样,并没有理会从C语言到机器语言的编译过程具体是什么样。
二、编译的四个步骤
gcc的编译流程分为四个步骤,分别为:
・ 预处理(Pre-Processing)
・ 编译(Compiling)
・ 汇编(Assembling)
・ 链接(Linking)
(1)编译预处理(Pre-Processing)
先输入这一行命令:gcc -E 目标文件.c
![]()
回车后就被刷屏了….

把这些代码导入到一个hello2.c的文件中
![]()
打开后
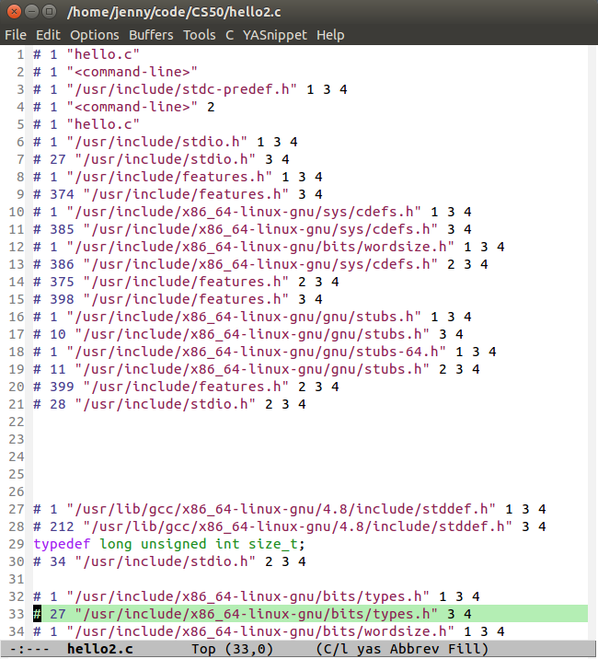
这是什么鬼!长这么奇怪= =
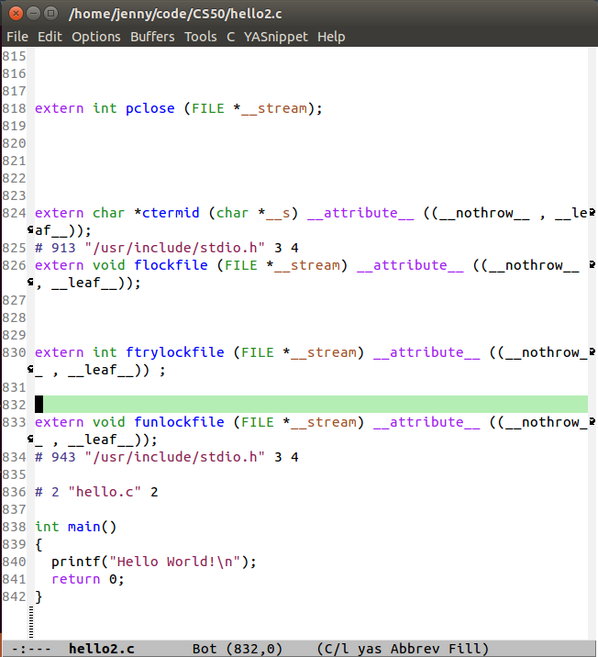
哈,居然有800多行,拉到最后终于看到熟悉的 “hello world!”代码片段惹!
这就是编译预处理啦~ 搜了一下什么是编译预处理
【摘】预编译的主要作用如下:
●将源文件中以”include”格式包含的文件复制到编译的源文件中。
●用实际值替换用“#define”定义的字符串。
●根据“#if”后面的条件决定需要编译的代码。
是嘛~刚刚刷屏那个就是把源代码中 #include <stdio.h> 这一行替换成了834行代码..
再拿宏定义试试,注意第3行

相同操作之后,对比预处理之后的.c文件

喏,836行之前没有区别!只有原来 #define name “Jenny” 那一行消失了,取而代之的是源代码中 printf(“Hello %s\n”,name); 中的name 被换成了 ”Jenny”

这就是传说中的,define只做“文本替换”啦
(2)编译(Compiling)
下面用 gcc -S 目标文件.c 来编译,用C语言代码 生成 汇编语言
![]()
打开编译后的 hello.s 文件

又是什么鬼,完全看不懂….
(3)汇编(Assembling)
用 gcc -c 目标文件.s 把
![]()
打开 hello.o二进制文件

这就是传说中的机器码了,你看到中间的 “hello world!” 了吗?
*Bonus 直接修改二进制文件
让我们改改机器码试试!→_→

改成 no zuo no die ….
运行试试

玩坏了 ..>_<.. 一定是字节不一样!!

改成hello jenny

这样就行啦!
*Bonus 用十六进制看机器码!
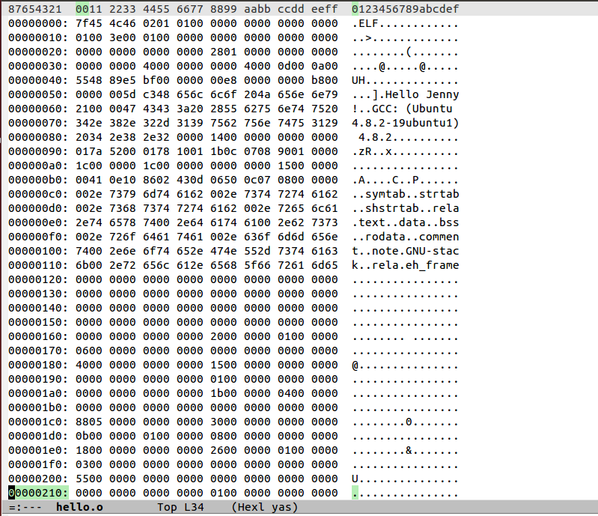
哈哈哈,有点像传说中的10101010串了吧!我不知道怎么通过二进制查看机器码….

再改成nozuonodie!!
这次成功了

(4) 链接(Linking)
刚刚一直到这个步骤,其实代码都不能执行。可执行文件 a.out 是我之前一步gcc hello.c生成的。
最后一步链接,需要在二进制文件 hello.o 的基础上,生成可执行文件 .out

命令为 gcc hello.o
列出当前文件夹下面的文件,可以发现只有 hello.out 是绿色的,并且最左边一堆rwx里面只有hello.out带有x,那些rwx表示的是”read”,”write”,”execute”的权限啦!