发生在这一年的八件大事
- 选择科大
- 字幕组 & MOOC
- 高考人品爆发 & 高中毕业
- 果壳实习 & 北京玩耍(706)
- 加入LUG
- 万有青年养成计划:MOOC 进中学
- 谈恋爱
- 放弃物理 & 转院
感谢
- 陈皮
- 梁昊
- boj
- 教育无边界字幕组
- 果壳网 & MOOC 学院
- 科大
发生在这一年的八件大事
感谢
科大个人主页网址是:home.ustc.edu.cn,全称是“中国科大学生FTP/主页服务器”,简单来说就是:科大给学生提供每人 300MB 的静态空间,你可以通过 HTTP 或者 FTP 两种方式访问。
其实科大也给教师提供“中国科大教工FTP/主页服务器”的服务,网址是:staff.ustc.edu.cn,貌似提供的空间会多一些,其他应该差不多。
明天就要出发回学校了,记得上次动身出发的前一个晚上我刚刚买了这个域名…
寒假很快就结束了,感觉过的很失败= = 每天睡到11点…然后还要午睡,除了睡觉就是写代码和看电影。结果好像什么也没写出来,拖着的任务更是几乎都没有完成~(>_<)~
想想以后寒假不回家这么长时间了(2.5-2.26),还是出去做些有意义的事情吧!
写一个 Python 爬虫其实挺容易的,也许过程中需要不停的调试,但爬虫的代码绝对短小精悍!
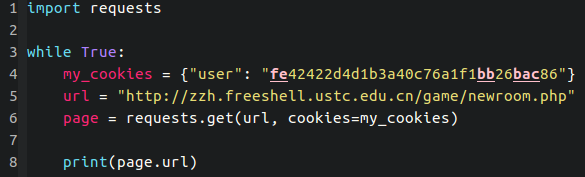
这就是我昨天把郑子涵五子棋网站搞挂的 Python 爬虫,文件名为 spider004.py。没错是我写的第四个爬虫…今天为了防止我继续恶意开房,他给网站加了验证码。目前我还无能为力= =
要写一个爬虫,首先你得懂 HTTP 协议的一些东西。我当时是看了这篇文章《HTTP协议详解》。我简单说下自己的理解:
当你用浏览器访问网页的时候,其实是经历了这么一系列的过程:你通过浏览器发出 HTTP 请求 (HTTP Request),发送请求有多种方法,常见的两种是 GET 和 POST。网页的服务器端收到你的请求进行处理后,就会给浏览器响应 (HTTP Response)。而 HTTP Request 和 HTTP Response 都是有参数哒,你可以通过 F12 来看。
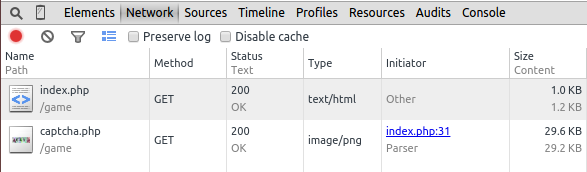
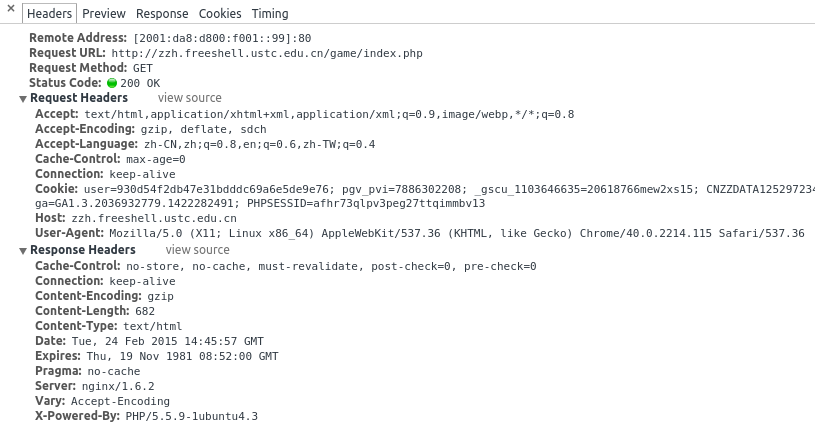
这很好理解,因为交互各种各样,访问不同的网址,是否登录账号,用什么浏览器,甚至在不同的时间发起请求,都会导致 HTTP Request 的不同。而服务器端挂了,状态码(status_code) 可能是 502 Bad Gateway,又或者 404 Not Found,这都是平时常见的错误,就是 HTTP Response 的一部分。(你可能会把它统称为:“ 啊,网页怎么打不开了!”,其实打不开也是有不同的原因的)。
差不多先了解这些,之后写爬虫的过程中,我们还会常用 F12,利用 HTTP Request/Response 的信息来调试。
所谓的网页爬虫,就是模仿浏览器向服务器发送特定的请求,并且返回获取的内容。而 Python 为此提供了一个很好用的模块,Requests 模块。
我最早是看了这个教程《HTML Scraping》,并且按照上面操作了一遍。这个教程提到抓取网页内容可以用的两种定位方法 XPath 和 CSSSelect,虽然我都没学会..
然后还看了这两个教程,一个是《Requests: HTTP for Humans》官方文档,另一个是《Using Requests in Python》简单教程。
我们可以简单的演示一下(终端中打开python3):
>>> import requests
>>> page = requests.get("http://www.baidu.com")
>>> page.url
'http://www.baidu.com/'
>>> page.status_code
200
>>> page.headers
(省略)
>>> page.text
(省略)
如果你需要的是抓取网站获取的信息(显示的HTML文件),可以把 page.text 部分输出到文件中。
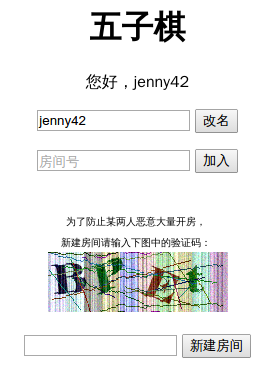
我观察到五子棋网站下棋开的房间是随机6位数,而且保存所有的棋盘信息,也就是你下完棋哪怕两个人都退出了以后,房间还是被占用的,你们还可以之后再进去继续玩。也就是,“如果我把所有的房间都开满了,那其他人没法开新的房间,也没法再已经被我开的房间里下棋了”←我对网站的攻击就是基于这个思路。
首先,自己打开浏览器里的匿名窗口操作一遍(匿名窗口是防止 cookie 混乱),并且按F12打开控制台, 观察到我新建房间时发出的请求获取的文件,如
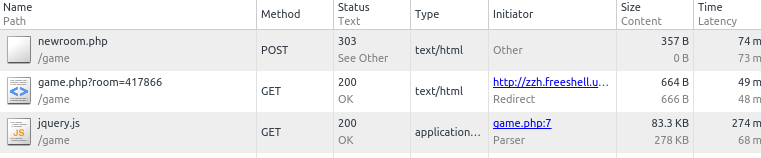
戳进去,拿到 cookie 和 url,然后作为代码的参数
我把它写成了死循环…然后,运行这个代码。每次访问http://zzh.freeshell.ustc.edu.cn/game/newroom.php这个url,它就会返回一个新房间的地址,相当于完成了开房的动作。
以上这小段代码也是我经过一会时间修改才搞定的…
确认可行之后,我开了10个终端…一起刷,结果一个多小时后,网站就挂了。。。整个 freeshell 登不上去了。经神秘管理员重启之后,网页上已经无法新建房间,随机输入一个房间号都有一个叫做 root 的玩家在里面。
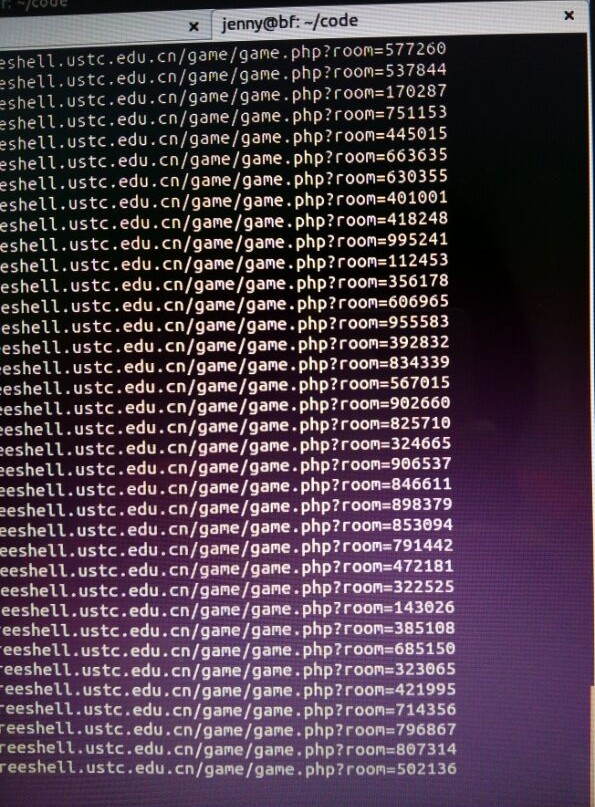
肇事者表示刚刚学会写爬虫所以拿了个好朋友的网站来玩…神秘的 freeshell 管理员其实是帮凶,他不仅指导我写脚本,而且在我开始攻击之后,突发奇想想要测试该 freeshell 的抗压能力…搞得该站长一直以为是有人通过 2081号 freeshell 攻击。我做了坏事,看对方没有反应,先是主动上去报了 bug(“哎呀,你的五子棋没法玩了耶”→好贱),最后被查出来以后主动承认并道歉…我表示一开始还挺兴奋,后面觉得这么做还是挺不好的…要是对方生气了呢,是吧?
这本书,从 2014.11.28-2015.2.12 前后拖了两个多月才“看完”…
感觉这本书说是“硅谷创业之父Paul Graham文集”,更像是Paul Graham的吐槽文。他在书中提出了很多“新观点”,然后各种论述为什么他的新观点是对的,常常很罗嗦…如果你平时比较喜欢主流路线,可能这本书可以洗脑;如果你平时比较叛逆,那这本书在你看来“哈,这一点我之前没想到!”,”额,我也是这么想的…“。
感觉适合茶余饭后闲着没事翻翻,毕竟也没有什么”干货“,都是作者主观表述,不过经常有些非常黑的表达…
首先我很讨厌这本书的第一章,【1 为什么书呆子不受欢迎:他们的心思在别的地方】,因为我觉得“啊,他说的我都懂啊,不痛不痒的…好啰嗦”。
接下来【2 黑客与画家:黑客也是创造者,与画家、建筑师、作家一样。】也一样,无非就描述了写代码好比创作,黑客和画家是相似的。却花了好多篇幅论证。
把这两章放在前面直接导致我看的很慢…没什么兴趣
最后部分好几章都在鼓吹 Lisp 语言,基于自己的水平太低,不仅对 Lisp 不了解,而且没有一门熟悉的语言,实在是没有判别能力来看 Paul Graham 对 Lisp 语言的评价。而且对语言的评价因素也不了解,所以 14 章直接翻翻就过去了。
【13 书呆子的复仇:在高科技行业,只有失败者采用“业界最佳实践”。】
【14 梦寐以求的编程语言:一种好的编程语言,是让黑客可以随心所欲使用的语言。】
【15 设计与研究:研究必须是“新”的,而设计必须是“好”的。】
【4 良好的坏习惯:与其他美国人一样,黑客的成功秘诀就是打破常规。】
【5 另一条路:互联网软件是微机诞生后的最大机会。】
【6 如何创造财富:致富的最好方法就是为社会创造财富。创造财富的最好方法就是创业。】
刷新我对财富的态度:“财富是创造出来的,财富的总和不是固定的!!”
【10 编程语言解析:什么是编程语言?为什么它们现在很热门? 】
【11 一百年后的编程语言:一百年后,人类怎样编程?为什么不从现在开始就这样编程呢? 】
【12 拒绝平庸:别忘了你的对手与你一样,能用任何想用的语言编写互联网软件。】
这几章让我开始思考对待编程语言的态度,感觉高度不一样了。进而反思,学校教C语言,学生大部分是时候是在专注它的细节,怎么把代码写对…而很少会去思考语言本身,它的设计怎么样,语法怎么样。
还有一个就是对互联网软件的概念。
【3 不能说的话:如果你的想法是社会无法容忍的,你怎么办?】
这一章有些讽刺,自己之前是没思考过这个问题。所以,也许有部分参考价值,不过我现在貌似不是很关心这个…
【7 关注贫富分化:“收入分配不平等”的危害,会不会没有我们想的那样严重?】
这章提出了对贫富分化的新观点。。。
【8 防止垃圾邮件的一种方法:不久前,许多专家还认为无法有效地过滤垃圾邮件。本文改变了他们的想法。 】
原来垃圾邮件的过滤器差不多是这个样子…
http://zh.learnlayout.com/box-sizing.html
万岁!妈妈再也不用担心我不会算 padding, margin, content 的大小了~
学习完这门课的 Html 部分之后,继续学 CSS部分。但感觉基本的 CSS 属性在 Html 部分都讲了,而 CSS 和 Html 拆分开之后,我觉得课程比较枯燥。因为我常常无法把最新学的 CSS 属性用到我写的网页中。以至于到了这门课最后一小节,我发现好多 CSS 属性我根本没有掌握…特别是 Position 和 框模型这一部分…感觉好沮丧
上次的笔记讲了我跟着这门课学习 HTML 的过程和心得,之后我把个人主页的 HTML 和 CSS 拆分开了。


在 <head>标签中插入这么一行
<link type=”text/css” rel=”stylesheet” href=”stylesheet.css” />
把 CSS 和 HTML 拆开,就好像开始给 Python 写函数,可以减少重复代码。HTML 专注于文档的结构,而 CSS 则负责页面美观。
这部分内容可以说我跟着 Codecademy 学的晕头转向的,学完这门课的时候还不怎么会用。
最后一个项目要我们用学到的东西做个人主页,花了一天时间才做出一个简单的页面。
在这个过程中,大部分时间都在鼓捣框模型的 margin, padding,而且第一次做出来都是按px写的,后来发现这样有一个问题:不同分辨率的电脑显示效果很不一样。于是又全部改成了em,但是还有一些问题没有解决。
总之,写出这个网页,深刻让我体会到了手写 CSS 的痛苦之处,因为,有无数个细节等着你去处理…
不过写这个网页的过程中,我完成了 Codecademy 上的这门课。

我觉得完成这门课之后看这个教程特别合适,尤其是在我看到 Position 这节的时候:
“为了制作更多复杂的布局,我们需要讨论下 position 属性。它有一大堆的值,名字还都特抽象,别提有多难记了。让我们先一个个的过一遍,不过你最好还是把这页放到书签里。”
看到教程这么说,我感到很欣慰。
英文学一遍之后,再看看中文表述。这个教程写的非常精致,页面美观,而且说明的方式很特别:代码加实际效果。看完教程,不仅对框模型和定位清楚了一些,而且还知道了很多CSS3的新属性!
比如:不需要再苦苦算padding, margin。发现Codecademy上面教的东西不算很新,现在CSS3以及有很多新办法使得处理问题简化了很多。
这启发我们,当你觉得解决问题的方法很繁琐的时候,应该学学 HTML5 和 CSS3 里面的奇技淫巧。
在看上面教程【媒体查询】这一节的时候,我随便翻了几个网站。比如惊讶的发现MOOC学院的响应式设计就做的很差(戳这个贴子),又看了下科大镜像(mirrors.ustc.edu.cn)的首页,发现没有做媒体查询。于是就尝试动手改进一下它的CSS。

先加入到 Mirrors 的 gitlab 小组中,下载到源代码。又看了一些媒体查询的文档。做了如下改动:
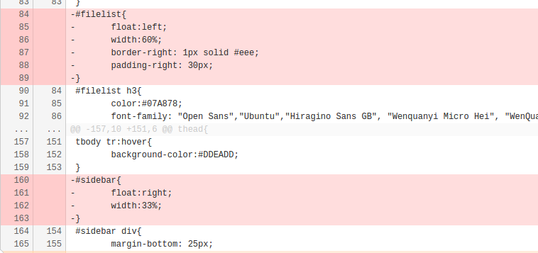
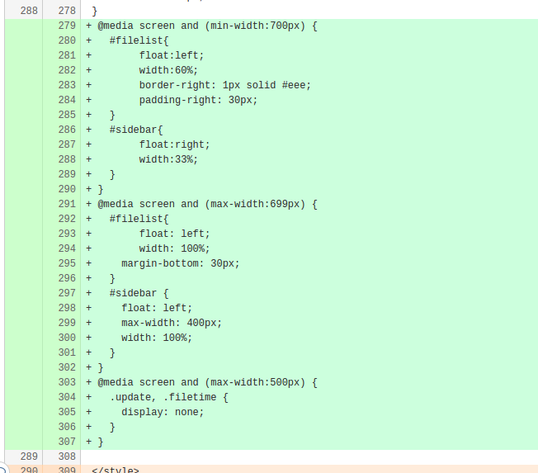
把红色部分代码改成绿色部分,也就是添加了媒体查询(其实就类似一个选择语句,如果页面大于临界尺寸,就按方案1显示,否则按照方案2显示。)
效果1:当页面宽度小于某一临界值时,原先在页面右边的导航栏到了页面下方。

效果2:当页面宽度更小时,原先文件列表第二列的更新时间被隐藏了(display:none)

哈哈!当自己的修改在实际网站上面采用的时候,还是很受鼓舞的!
中科大开源软件镜像,目前是中国大陆高校访问量最大,收录最全的开源软件镜像。我在来科大之前就听说过~
看完了这个非常赞的教程,我觉得我下一步的学习应该是:CSS框架,手写CSS能够巩固你刚学的CSS基础,但是要写出一个漂亮的、功能丰富、兼容性良好的网页,所需的CSS太复杂了。先学习使用框架,可以学习框架里面的页面布局、命名方式、特殊处理等等,待CSS技能更加厉害的时候,就会懂得选择适合自己的框架或者是手写一个更完善的网页CSS。(我现在如果手写网页CSS,会浪费很多时间在框模型等等的细节处理上面)。
—
好啦~我觉得 Codecademy 上面 HTML&CSS 这门课,给我入门起到了很大的帮助。1.22日开始学这门课,到现在刚好花了10天。接下来我可以尝试去解决一些实际问题,同时查文档,搜索特定的问题。就像小孩子学会扶着栏杆走路。
已经不需要特定的入门书籍了。