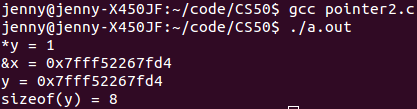
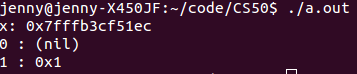
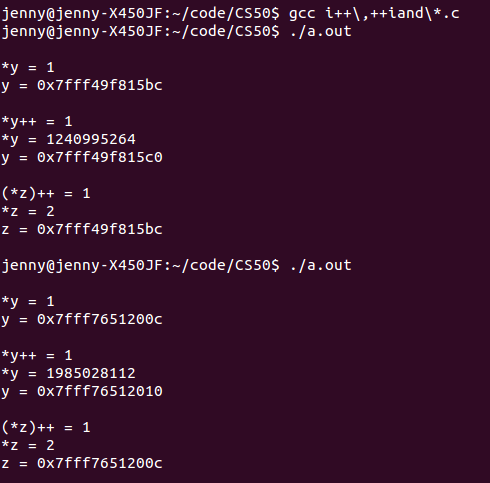
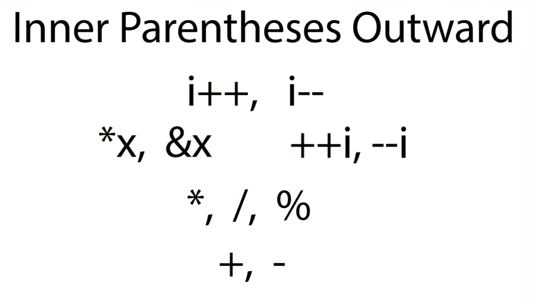| 书名 |
作者 |
出版社 |
版次 |
开始阅读 |
截止阅读 |
| 浪潮之巅 |
吴军 |
电子工业出版社 |
第一版 2011年11月第5次 |
2014-9-23 |
2014-10-29 |
浪潮之巅这本书是在李博杰的推荐下开始看的。
关于作者:吴军
书籍目录:百度词条-浪潮之巅(和我看的版本是一样的)
内容回顾
从目录可以看出,这本书花了一半以上的篇幅介绍各个互联网公司,准确的说是曾处在技术浪潮之巅的公司。介绍了它们的兴衰历程,以至于好长一段时间(主要在书籍的前半部分)我一直觉得看的都是各种令人伤心的故事,而且公司看多了那些故事就记不清了,大概记住了这个公司主要是做什么的,曾经多么辉煌…所以,介绍公司这部分我不是很感兴趣(虽然第一次知道一些公司的过去也是蛮好玩的)。
除此之外,本书的另一半篇幅则用于介绍:计算机工业生态链、硅谷、风投、信息产业规律、斯坦福、投行、商业模式、互联网2.0、金融风暴冲击、云计算、下一个Google等内容。这部分偏向于总结出规律性、提到与商业的联系,我觉得正是本书出彩的地方。
正如作者在序言中所说:
我会谈一谈我对每次浪潮的看法,对上述每个公司的看法,以及对其中关键人物的认识。在极度商业化的今天,科技的进步和商机是分不开的。因此,我也要提到间接影响到科技浪潮的风险投资公司,诸如 KPCB 和红杉风投(Sequoia) 以及百年来为科技捧场的投资银行,例如高盛 (Goldman Sachs) 等等。
而作者在后记中再次提到:
我用心去了解商业的规律,本意为了投资;不仅仅是为了让我管理的基金投资有好的会报,更重要的是让我一生的时间投资有效。对我来讲,时间才是我最大的财富,我要把它投到最有意义、最有影响的地方去。经过我的学习、思考和实践,我认定这样一个规律:科技的发展不是均匀的,而是以浪潮的形式出现。对个人来讲,看清楚浪潮,赶浪潮,便不枉此生。
这便解释了本书为什么如此关注商业,并且书名为什么叫做“浪潮之巅”。
收获、联想
看完这本书自然是知道了很多公司的黑历史,算是被科普了一些互联网领域领域的常识,用李博杰的话来说作为谈资是没问题的…(聊天嘛)。
1.公司
其实我以前从来没考虑过将来进入公司工作…(额,之前总想着搞科研…),也是暑假进入果壳实习之后才开始慢慢了解公司的运行。这本书更是加深了我对互联网公司的了解,比如:
- 我们以后还会多次看到,当一家公司没有人对它有控制权时,它的长期发展就会有问题
- 一个公司创始者的灵魂常常会永久地留在这家公司,即使他们已经离去。
- 一家公司的市场份额超过50%以后,就不用再想去将市场份额翻番了。
- 一个风投公司要想成功,光有钱,有眼光还很不够,还要储备许多能代表自己出去管理公司的人才。这也是著名风险投资公司比小投资公司容易成功的原因之一,前者手中攥着更多更好的管理人才。
2.创业和风投
在【第11章:硅谷的另一面】中花了较大篇幅提到创业的问题,总的来说就是创业成功是很不容易的。一家小公司想要成功,必须具备很多条件,从创始人到团队、从技术到商业模式、执行力判断力、外部环境还有好运气。(具体看185页)而想要在创业时有高回报:
要做到高回报必须首先选对题目。 其次,创业的题目不能和主流公司的主要业务撞车。 除此之外,一个好的题目还必须具备以下几个条件。 1.这个项目一旦做成,要有现成的市场,而且容易横向扩展。(Leverage) 2.今后的商业发展在较长时间内会以几何级数增长。 3.必须具有革命性。
一个月前看到创业和团队管理的内容,我都会想到字幕组管理是否合理和MOOC进中学项目是否具备这些条件。甚至联想到果壳万有青年养成计划主办方和计划发起人有着类似风投公司和创始人的关系。
风投是新兴公司的朋友和帮手,因为它们和创始人的基本利益是一致的。但是通常也有利益冲突的时候。
看到红杉资本对创业者、创业公司的要求就更有感触了,顿时就联想到MOOC进中学项目文案的事情,原来项目文案应该这样写…
找红杉风投前,创业者要准备好一份材料,包括
1.公司目的(一句话讲清楚)。
2.要解决的问题和解决办法,尤其要说清楚该方法对用户有什么好处。
3.要分析为什么现在创业,即证明市场已经成熟。
4.市场规模,再强调一遍,没有十亿美元的市场不要找红杉。
5.对手分析,必须知己知彼。
6.产品及开发计划。
7.商业模式,其重要性就不多讲了。
8.创始人及团队介绍,如果创始人背景不够强,可以拉上一些名人做董事。
9.最后,也是最重要的—想要多少钱,为什么,怎么花。
公司目的、产品介绍,都要做到一句话说清楚。这一点我们应该记住。
3.计算机行业规律
本书不仅讲述科技工业的历史,更重在揭示它的规律性
计算机行业的发展规律:
信息行业的规律性:
4.硅谷的摇篮——斯坦福:
这一章对我也有较大的启发,按书中所说,斯坦福和工业界的联系会比其他大学紧密一些:
其实和工业界保持联系,并且为工业界做研究,对于创业者来讲,最大的好处在于能够看清产业发展的方向并找到新的机会。这个潜在的好处对于年轻的学生,甚至比对于资深的教授们更明显,因为年轻人更愿意尝试。
开放校园的真正含义在于像斯坦福那样,让大学融入社会。“开放”是斯坦福的“本”,而厂校结合是它的“用”。后者保证了大学开放校园的具体实施。
年轻的学生最有益的校园环境就是那种最贴近今后真实生活的社会环境。
对于大部分学生来讲,在斯坦福的岁月里学习到的社会知识比课堂知识对自己的一生更有帮助
斯坦福为硅谷输送人才,这样的互利模式的确不错。
5.金融、商业和科技
第13章 讲述风险投资是创业公司幕后英雄,而第16章则讲述了华尔街的贪婪,介绍了美国的金融体系,科技公司的上市过程等等。正如文章第一部分所说,商业模式、金融体系、资金运作等等对科技公司(进而对科技发展)都有很大的影响。由于这部分我自己没弄清楚…就不多说了
推荐阅读章节:
第11章 硅谷的另一面
第13章 幕后的英雄—风险投资
第15章 硅谷的摇篮—斯坦福大学
第16章 科技公司的吹鼓手—投资银行
第17章 挑战者—Google 公司
吐槽笔记
边看书的时候有记一些笔记,吐槽在这些地方…
豆瓣读书:我对《浪潮之巅的笔记》(我想知道豆瓣有没有客户端可以记笔记)
涂书笔记:《浪潮之巅》(涂书笔记居然是百度家的…)
现在看来,边看书边吐槽的笔记还是挺有帮助的,可以让我快速回想起本书的内容。
外界评价
这本书的评价比较多,我看的是第一版(豆瓣链接),被吐槽错误非常多…不顾这本书对我相当于接触一个新领域,我并没有察觉出有哪些不严谨的地方。
而知乎这个问题:如何评价《浪潮之巅》这本书(周筠的回答)更是内容丰富,引出了一堆外链。
我还看了一些其他人的读书笔记:
由于我之前完全不了解互联网行业,因此读完这本书我的收获还是挺大的,总的来说这是一本有趣的书,也推荐感兴趣的同学阅读。
最后,这本书是从LUG书库借的,欢迎大家来LUG借书。